
We Submitted llms.txt to Google Search Console. 3 Days Later, It Was Powering AI Answers
Published: February 23, 2026
Read time: ~8 min
This is not a story about a magic trick. It's a story about a plain `.txt` file, an honest experiment, and a result we didn't fully expect.
We already had an `llms.txt` live - a simple Markdown file at our domain root, maintained and auto-updated via our Magnolia DXP pipeline. Not glamorous. If a real user clicks on it, they see raw text, no styling, no navigation, no CTA. It looks like 1994.
But we got curious: what does the AI web actually do with this file?
We ran this whole experiment to answer two questions:
1. Will an indexed Markdown-style text file influence Google rankings?
2. Will it boost AI citations (e.g., Google AI Mode sources) for brand/service queries?
We deliberately used `llms.txt` for the test because we already had it live, we already maintain it, and our Magnolia DXP pipeline can keep it automatically updated - meaning we weren't "creating content for the experiment," we were testing the *impact of the format + submission pipeline* with a file we'd keep anyway.
So on February 2, 2026 we did one thing: we submitted `https://www.dev5310.com/llms.txt` directly to Google Search Console. No sitemap entry. No internal links. Just the URL and a button click.
- Feb 2, 10:19 AM - Google crawled it. Same day.
- Feb 3 - Google AI Mode cited it as its #1 source on the first query
- Feb 5 - Still the lead citation. Different session.
- Feb 14 - 18 - 6 confirmed AI bots hit the file in 4 days
- Feb 20 - Cited in 3 out of 4 queries, across different topics
Here's what the logs show, what it means - and what it doesn't.
What is llms.txt?
`llms.txt` is a proposed web standard (Jeremy Howard, 2024) - a Markdown file at your domain root that gives AI systems a structured, token-efficient overview of your site's content.
The Setup

We, dev5310 GmbH & Co. KG, a Hamburg-based technical agency specializing in Enterprise Digital Experience Platforms (DXP) and Magnolia Gold Partner with 18 certified developers, are here for implementations and AI integration. We had a `llms.txt` live on our site - a structured Markdown file describing who we are, what we do, and which pages matter most.
On February 2, 2026, we submitted `https://www.dev5310.com/llms.txt` directly via the URL Inspection tool in Google Search Console.
What followed was faster than we expected.
The Complete Timeline

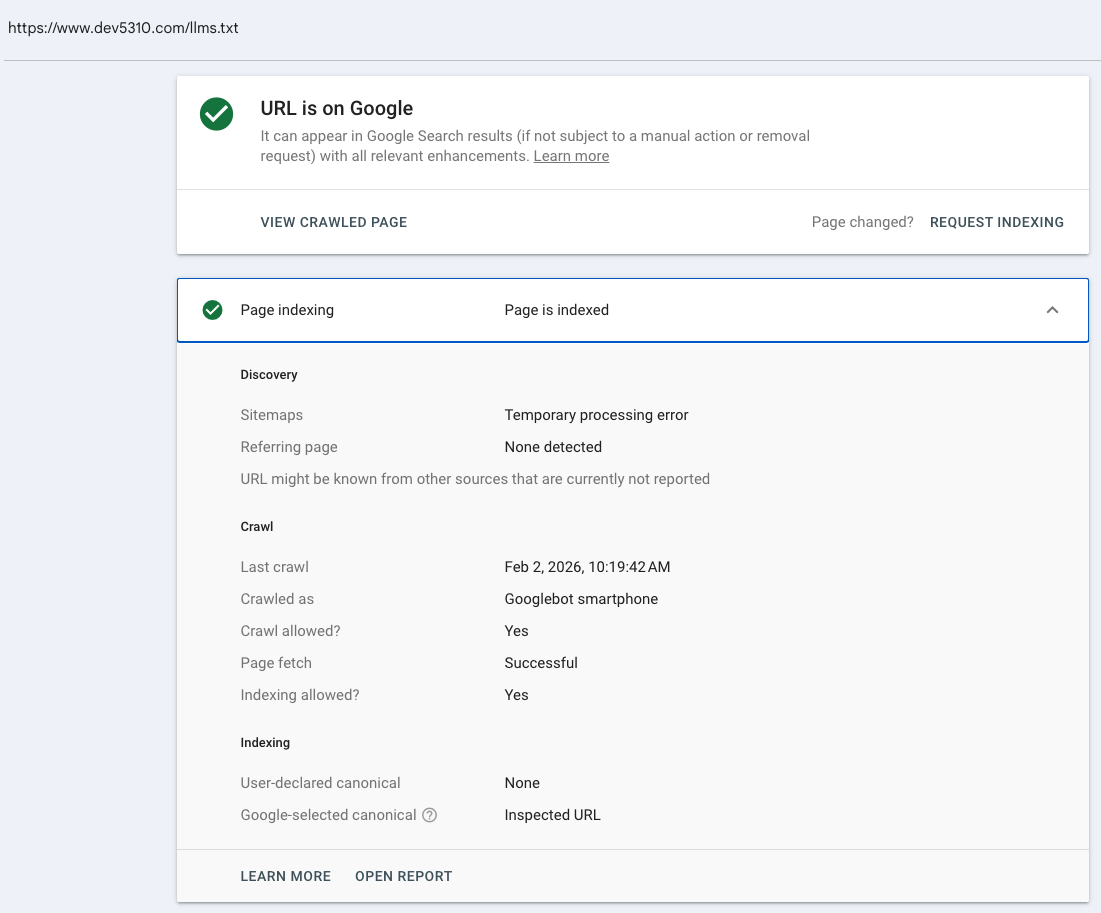
Feb 2, 10:19:42 AM - Google crawls the file the same day as our submission. Crawled as Googlebot smartphone. Page fetch: successful. Indexing: allowed.
The Search Console discovery data shows something important: **no referring sitemaps, no referring page detected.** Google found this URL solely through our direct submission request — no sitemap, no internal link, no existing SEO infrastructure pointing to it.
Google Search Console crawl details showing Feb 2 indexing with no referring page Screenshot 2026-02-23 at 13.34.39
{kind=link}

Feb 3, 11:34 AM - Search Console confirms: "URL is on Google. Page is indexed."
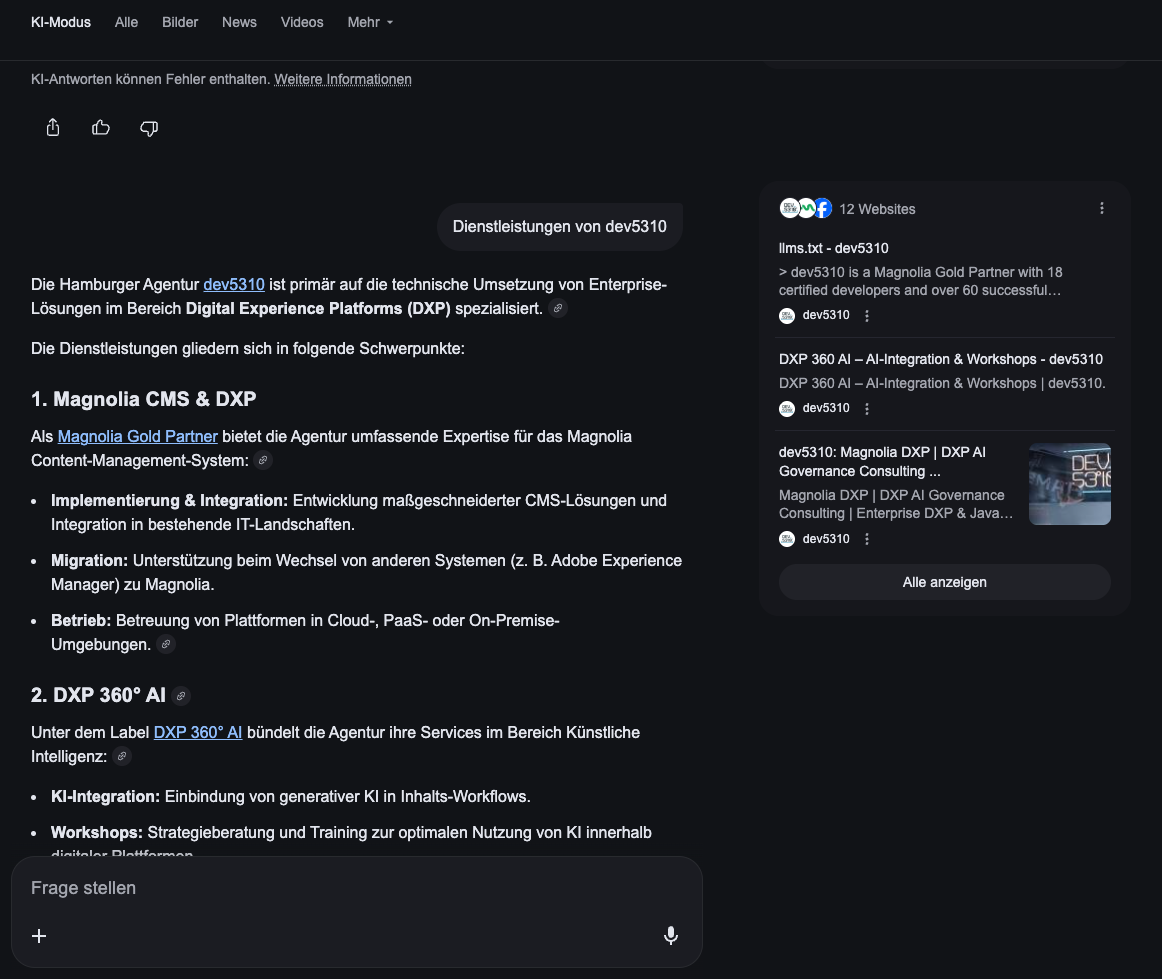
Feb 3, 11:36 AM - First AI citation. One day after the crawl, we query Google AI Mode with "Dienstleistungen von dev5310." The answer is detailed, structured, and accurate - covering our Magnolia Gold Partner status, DXP 360° AI services, and key offering details. In the cited sources panel: "llms.txt - dev5310" is the lead source.
Google AI Mode citing llms.txt on Feb 3 Screenshot 2026-02-03 at 11.36.13
{kind=link}
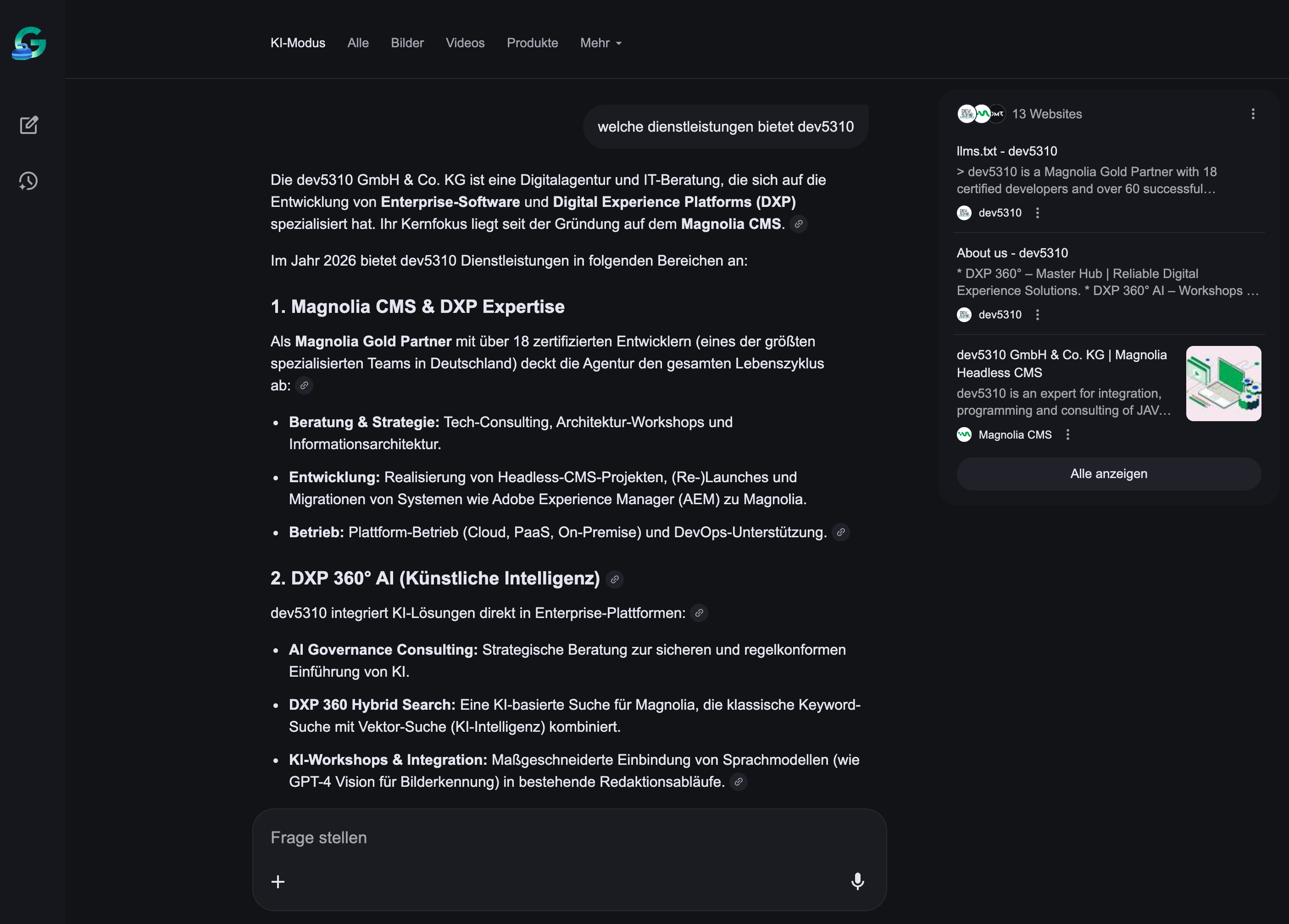
Feb 5, 09:59 AM - Second AI citation. Three days after the crawl, we query Google AI Mode again with "Dienstleistungen von dev5310." "llms.txt - dev5310" is again the lead source.
Google AI Mode citing llms.txt on Feb 5 Screenshot 2026-02-05 at 09.59.13
{kind=link}

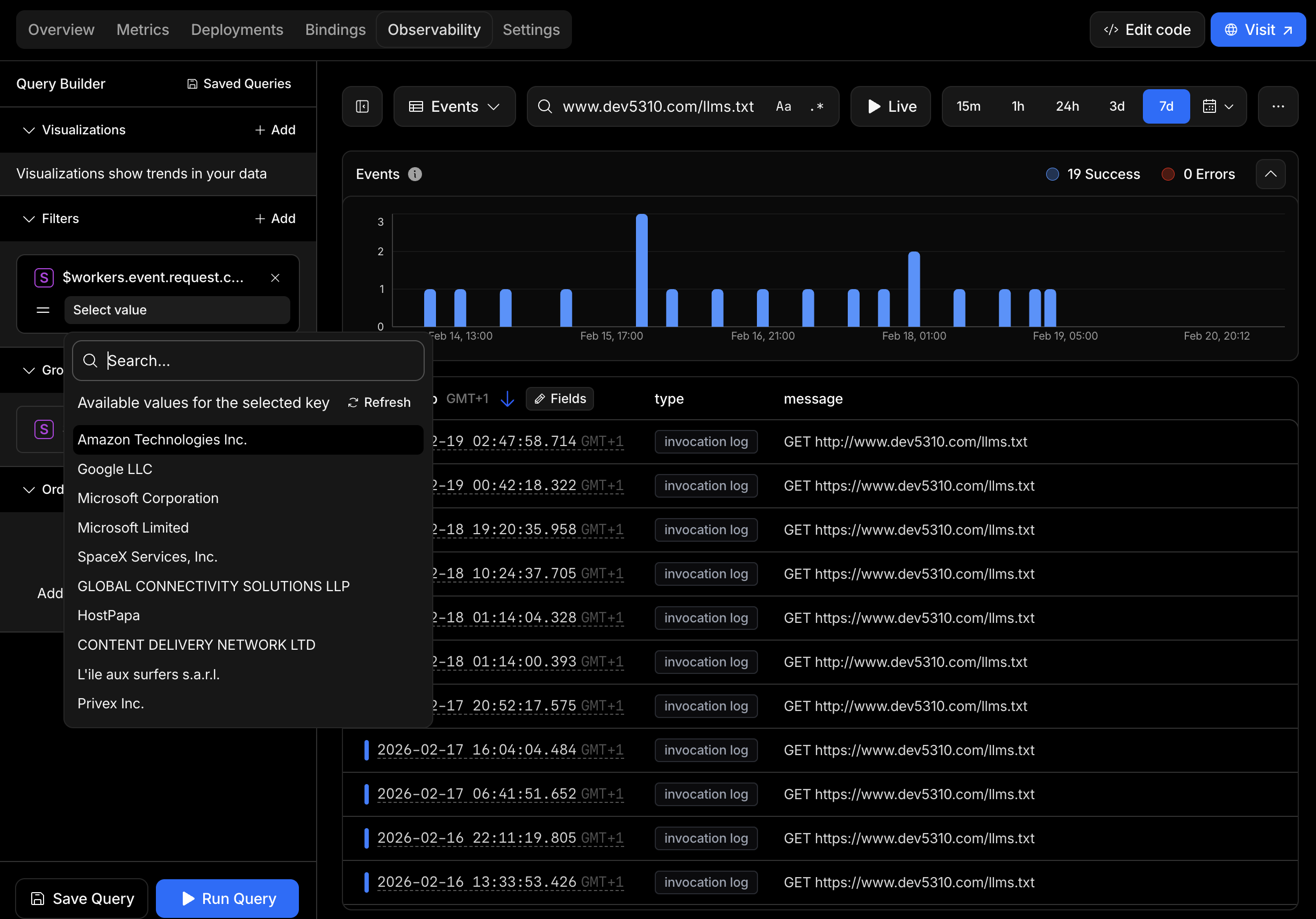
Feb 14-18 - Picking this up again to verify persistence. Our Cloudflare logs show a sustained wave of bot activity. In just four days: Googlebot/2.1 (Cloudflare-verified "Search Engine Crawler"), Google Web Rendering Service twice, OAI-SearchBot/1.3 (OpenAI's indexer, Cloudflare-verified "AI Search"), ChatGPT-User/1.0 (OpenAI's live browsing bot, Cloudflare-verified "AI Assistant"), Barkrowler (Babbar.tech), and BrightEdge. Six confirmed AI and search bots in four days - none of them invited via sitemap.
Cloudflare observability Screenshot 2026-02-20 at 20.50.08
{kind=link}

Feb 20, 22:04 PM - Query "Dienstleistungen von dev5310" again, 18 days later. `llms.txt - dev5310` was not cited in the sources panel, so asked for all sources and here it is cited, so the citation has held within Google AI Mode.
Feb 20, 22:58 PM - Query with new incognito window "Magnolia projects." Different question, same result: `llms.txt – dev5310` appears in the cited sources. The file is being used not just for company overviews but for specific project and service queries.
Google AI Mode citation Feb 20 - query: Magnolia projects Screenshot 2026-02-20 at 23.01.10
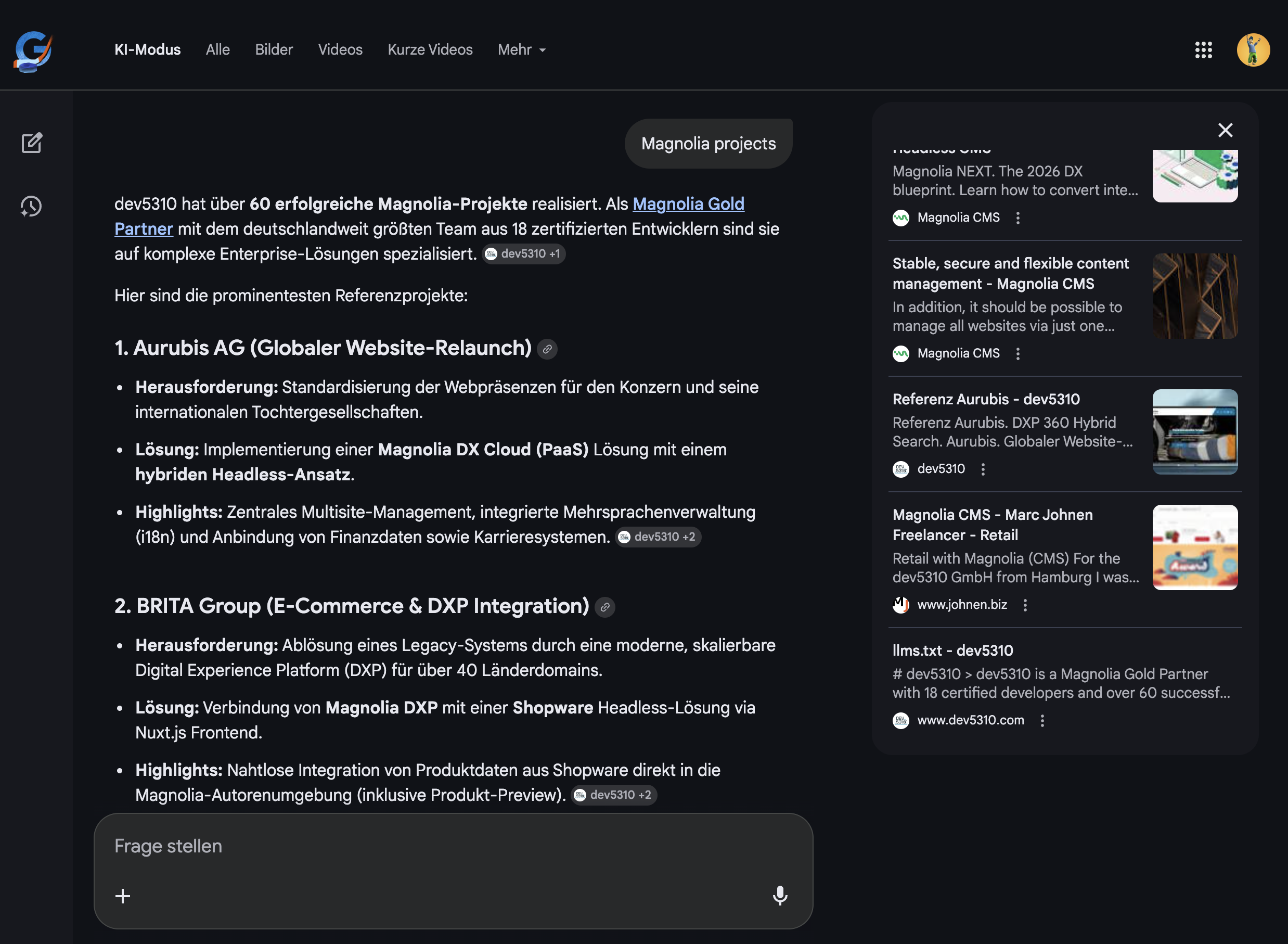{kind=link}

Feb 20, 23:01 PM - Query again "all sources for dev5310.com." Google AI Mode lists `llms.txt - dev5310` as its first and primary source - above all website pages - and explains, unprompted:
English translation:
"Yes, dev5310 has an indexed llms.txt file at dev5310.com/llms.txt. This file serves as a structured data source for AI models and crawlers. It contains a machine-readable Markdown summary of the company's identity and core competencies."
Original German response:
> "Ja, dev5310 hat eine llms.txt Datei unter der Adresse dev5310.com/llms.txt indexiert. Diese Datei dient als strukturierte Informationsquelle für KI-Modelle und Crawler. Sie enthält eine Zusammenfassung der Identität und Kernkompetenzen des Unternehmens in einem maschinenlesbaren Markdown-Format."
Google's AI isn't just citing our `llms.txt`. It's explaining to users what the file is and why it matters. That's a level of integration we didn't anticipate.
Google AI Mode explaining llms.txt as primary source Screenshot 2026-02-20 at 22.58.05
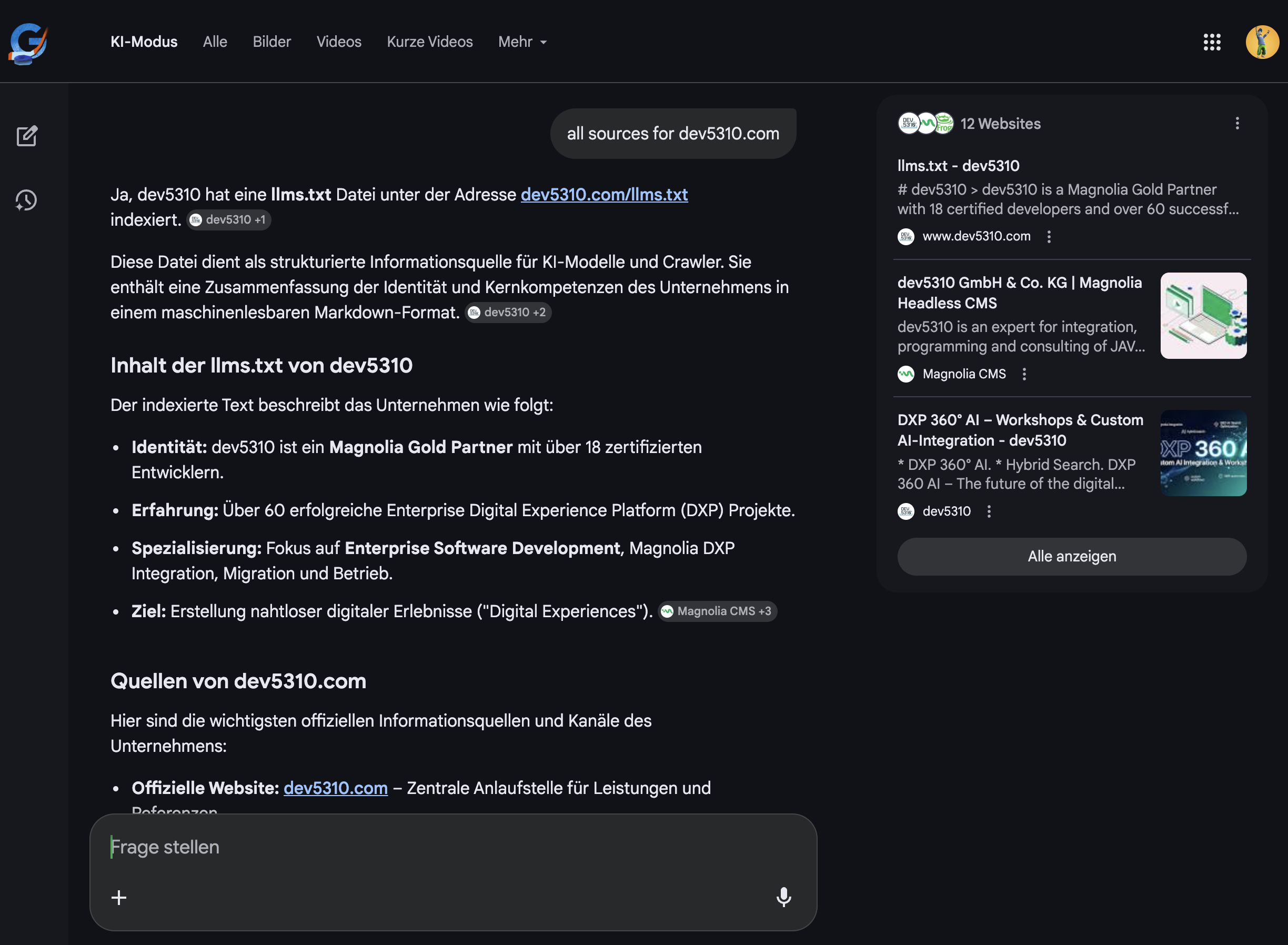{kind=link}
What Google's AI Actually Does With the File
The "all sources" query reveals the mechanism clearly. Google AI Mode uses `llms.txt` as the authoritative identity layer for the company - the structured anchor around which other sources are organized.
When a user asks about Magnolia projects, it references project pages *and* the `llms.txt` for context about who dev5310 is. When a user asks about services, the `llms.txt` frames the answer. When asked explicitly what sources exist, it leads with `llms.txt` before any other page.
This is the file functioning exactly as intended by its specification: as a curated, token-efficient index for AI systems - one that reduces the need to crawl and parse dozens of individual pages to understand what a company does.
Two OpenAI Bots, Two Different Jobs
Beyond Google, the Cloudflare logs show OpenAI sent two completely distinct bots.
`OAI-SearchBot/1.3` is the background indexer - it builds the knowledge base that ChatGPT Search draws from. It arrived from Microsoft Azure (Atlanta) and followed an internal link from our services page to find the file.
`ChatGPT-User/1.0` is active during live ChatGPT sessions, triggered when a user enables web browsing mid-query. It arrived two days later from a different Azure data center - a separate system, separate infrastructure, same file.
The file wasn't just catalogued for future use. It was retrieved during what was very likely a live user query about dev5310.
| Datum/Uhrzeit (UTC) | Identifizierter Bot | Kategorie | CF-Verified | Org/ASN | IP/Land |
| 2026-02-18 23:42 | Unbekannt (Privex Inc.) | Unknown Bot | – | Privex Inc. | US (Chicago) |
| 2026-02-18 18:20 | Unbekannt (AWS Chrome/131) | Unknown Bot | – | Amazon AWS | US (Ashburn) |
| 2026-02-18 09:24 | Unbekannt (Privex Inc.) | Unknown Bot | – | Privex Inc. | US (Chicago) |
| 2026-02-18 00:14 | Barkrowler/0.9(Babbar.tech) | SEO Crawler | ✅ Search Engine Optimization | L'ile aux surfers | FR (Paris) |
| 2026-02-17 15:04 | Unbekannt (HostPapa Chrome/144) | Unknown Bot | – | HostPapa | US (Buffalo) |
| 2026-02-17 05:41 | Google Web Renderer(Pixel 6 / GCP) | Google Crawler | – | Google LLC | US (The Dalles) |
| 2026-02-16 21:11 | BrightEdge BW/1.3 | SEO Platform Crawler | – | Global Connectivity LLP | BE (Brussels) |
| 2026-02-16 12:33 | ChatGPT-User/1.0(OpenAI) | AI Assistant | ✅ AI Assistant | Microsoft Ltd. | IT (Milan) |
| 2026-02-16 03:37 | Unbekannt (AWS bare UA) | Unknown Bot | – | Amazon AWS | US (Ashburn) |
| 2026-02-15 22:37 | curl/8.9.1 | Manueller Test | – | SpaceX/Starlink | ES (Madrid) |
| 2026-02-15 22:25 | OAI-SearchBot/1.3(OpenAI) | AI Search Engine | ✅ AI Search | Microsoft Ltd. | US (Atlanta) |
| 2026-02-15 08:38 | Google Web Renderer(Pixel 6 / GCP) | Google Crawler | – | Google LLC | US (The Dalles) |
| 2026-02-14 21:36 | Googlebot/2.1 | Search Engine Crawler | ✅ Search Engine Crawler | Google LLC | US (Omaha) |
| 2026-02-14 12:09 | Unbekannt (AWS bare UAMozilla/5.0) | Unknown Bot | – | Amazon AWS | US (Ashburn) |
| 2026-02-14 07:30 | Unbekannt (AWS bare UAMozilla/5.0) | Unknown Bot | – | Amazon AWS | US (Ashburn) |
Why It Worked: Schema.org + llms.txt Markdown as a Stack

The `llms.txt` didn't work in isolation. It worked because of how our website is already built.
Our Magnolia DXP custom integration stack generates schema.org structured data via JSON-LD fully automatically, with the context we input (content and context are curated manually - we use automation for structure, not substance) assembling context data and reusable fragments across the platform. Every key page carries machine-readable annotations: organizational data, webpage date, and additional structured metadata where applicable.
The `llms.txt` is a clean, human-readable - and AI-digestible - distillation of that same structured layer. It tells AI systems precisely what matters and where to find it, without requiring them to crawl and interpret every page independently.
JSON-LD on important pages + a curated `llms.txt` appears to be a complete enough signal for Google's AI pipeline to produce accurate, well-structured answers and cite the source directly - within 1 day of indexing.
What We're Doing Next
This was a proof-of-concept with one file covering the whole site. We're now keep to see how the pages will perform if we deliver them as markdown and schema.org to AI Bots.
Using our Magnolia's schema.org automation pipeline, we'll generate individual markdown for every significant page - services, case studies and person pages - and compile them into a comprehensive markdown.
In late March 2026, we'll repeat this test for the llms.txt markdown in google: same queries, full Cloudflare log analysis, and a direct before/after comparison of AI citation rates and answer quality. We'll publish everything here.
If the hypothesis holds, a schema-driven, page-level markdown should produce significantly richer AI source attributions and more accurate answers than a single summary file - turning our CMS's structured data pipeline into a direct feed for the generative web. Since Cloudflare was all over my LinkedIn Channel and even the news, credit to their idea: https://developers.cloudflare.com/workers-ai/features/markdown-conversion/ it works as a toggle switch but we first want to see how it will impact, before we use it.
The Honest Caveats
One agency, four queries, one 18-day window. We're not claiming a universal outcome and it has nothing to do with what llms.txt should be here for.
Peter Müller
Why we didn't create separate Markdown pages (and why `llms.txt` is different)
A real downside: a `.txt` file is not a nice user experience. If a human clicks `https://www.dev5310.com/llms.txt`, they'll see raw text in the browser - no navigation, no design, no CTA.
Also, important: we did not create "Markdown web pages for bots." Google's John Mueller has publicly pushed back on the idea of serving Markdown pages specifically for LLM crawlers (calling it a "stupid idea" and questioning why bots would need a page that no user sees), and the broader discussion touches the risk of bot-only versions crossing into cloaking patterns. Here the link.
That's why we used `llms.txt`: it's a single, honest, publicly accessible file that we already maintain, and it's meant as a compact index/summary layer - not a separate, hidden version of our website.
Next downside is, if you run a multi-language webpage in our study it shows that English is preferred over all other language.
What the research says
Broader research remains mixed. Search Engine Land tracked 10 sites after `llms.txt` implementation and found 8 of 9 showed no measurable change in AI-driven traffic. Google explicitly states it's not a ranking signal for Google Search. Neither OpenAI nor Anthropic has published documentation on how exactly they weight this file in generated answers.
What our own data confirms:
- Google indexed `llms.txt` within hours of a direct Search Console submission - no sitemap or internal link required
- First AI citation appeared 1 day after indexing
- Citation held consistently across 4 different queries over 18 days
- `llms.txt` was ranked as the #1 source when Google AI was asked to list all sources for our domain
- 6 confirmed AI and search bots hit the file in a single 4-day window
- Google AI Mode described the file's purpose - unprompted - to end users
The pipeline works. The variable is content quality and how well your structured data backs up what the file claims.
Sources
- Google / John Mueller on "Markdown pages for LLM crawlers":
Google's Mueller Calls Markdown-For-Bots Idea 'A Stupid Idea'
Google On Serving Markdown Pages To LLM Crawlers
- Summary of Google + Bing warnings re: bot-only Markdown versions and policy/cloaking risk:
Google and Bing say no: separate markdown pages for AI violate search policies
The Two Questions Answered
### 1. Will an indexed Markdown-style text file influence Google rankings?
**No.** Our tracked keywords remained in identical positions throughout the 18-day test window. The file does not appear in standard Google Search results - only when queried directly via `site:dev5310.com/llms.txt`.
Google has explicitly stated that `llms.txt` is not a ranking signal and compared it to the old `keywords` meta tag - technically readable, but without algorithmic weight.
**Verdict: Zero SEO impact.**
### 2. Will it boost AI citations for brand/service queries?
**Yes, in our case.** `llms.txt` was cited as the **#1 source** in Google AI Mode within 24 hours of indexing, held that position consistently across 4 queries over 18 days, and was described by Google AI itself as a "structured data source for AI models and crawlers."
Six confirmed AI bots (Googlebot, OAI-SearchBot, ChatGPT-User, and others) accessed the file in a 4-day window.
**Verdict: Strong GEO/AEO signal - when combined with existing schema.org infrastructure.**
What We Actually Learned
### The honest limitations first
A `.txt` file is not a webpage. If a user clicks `dev5310.com/llms.txt` they get raw Markdown in a browser tab - no design, no CTA, no context. It cannot replace a proper About page, a service page, or a structured landing page. Don't build your digital presence on a text file.
And the SEO impact? Zero, by Google's own statement. `llms.txt` is not a ranking signal. One large-scale study across 300,000 domains found no measurable correlation between llms.txt and better AI citations or organic rankings. Your rankings live or die by content quality, technical SEO, and backlinks - not file formats.
### Why we still think it's worth it
We already had the file. Our Magnolia DXP integration auto-generates and maintains it - it costs us nothing to keep it updated. That changes the calculation entirely.
For teams in the same position: if your CMS already generates structured JSON-LD and you have a clean content model, `llms.txt` is a quick implementation with perhaps an upside.
Not because the filename is magic. But because a well-structured, token-efficient summary of your brand - served at a predictable path - is accurately what AI crawlers want. Ours found it, read it, and started citing it. Across Google AI Mode, OAI-SearchBot, and ChatGPT-User.
### What this experiment was — and wasn't
+ A real test of a file we already maintained
+ Evidence that the pipeline from submission → crawl → AI citation works
+ Proof that `llms.txt` functions as an **authoritative identity layer** in AI Mode
- Not proof of universal results
- Not a ranking strategy
- Not a substitute for strong content on actual pages
### What we'd recommend
1. If you have `llms.txt` already → submit it to Search Console today
2. If you don't → write one only if your content model is clean enough to summarize honestly
3. In both cases → combine with Schema.org JSON-LD on your key pages
4. Watch your logs for `OAI-SearchBot`, `ChatGPT-User`, `Googlebot`
`llms.txt` is not SEO. It's not GEO either, not officially. It's AI infrastructure that costs almost nothing to deploy — and in our case, started working in 24 hours.
Meet the Expert

Peter Müller
Founder, Consultant & DXP AI Expert
Technical Project Manager at dev5310 with 15+ years of experience in Digital Experience Platforms. Magnolia Certified and specialist in AI integration in enterprise environments.
FAQ
Below are the most common questions we've received about our setup and results.
How did we integrate it into the DXP?
`llms.txt` was placed directly in the root path as a first-shot version - the initial implementation was intentionally minimal. A static file served via Cloudflare Worker at root path, no sitemap entry, no redirects.
Our Magnolia DXP custom integration stack generates schema.org structured data via JSON-LD fully automatically, with the context we input (content and context are curated manually - we use automation for structure, not substance) assembling context data and reusable fragments across the platform. Every key page carries machine-readable annotations: organizational data, webpage date, and additional structured metadata where applicable.
Does llms.txt affect Google rankings?
We have no indication that our ranking was changed. Our tracked keywords are still in the same position and did not change within the 18-day test timeframe. We will monitor this closely. The file does not appear in standard Google Search results - only when queried directly via `site:dev5310.com/llms.txt`.
How fast does Google index llms.txt?
Same day. In our case: Google crawled the file within hours of a direct Search Console submission. The URL was confirmed indexed the same day (Feb 2, 10:19 AM crawl). No prior SEO infrastructure required.
Which AI bots read llms.txt?
In our case, we found the following bots accessing the file during Feb 14–18:
| Bot Name | Cloudflare Category | Notes |
|----------|-------------------|-------|
| Googlebot/2.1 | Search Engine Crawler | Primary Google crawler |
| Google Web Rendering Service | Search Engine Crawler | Appeared twice |
| OAI-SearchBot/1.3 | AI Search | OpenAI's indexer for ChatGPT Search |
| ChatGPT-User/1.0 | AI Assistant | Live browsing bot during user sessions |
| Barkrowler | - | Babbar.tech crawler |
| BrightEdge | - | SEO platform bot |
Six confirmed AI and search bots in four days - none of them invited via sitemap.